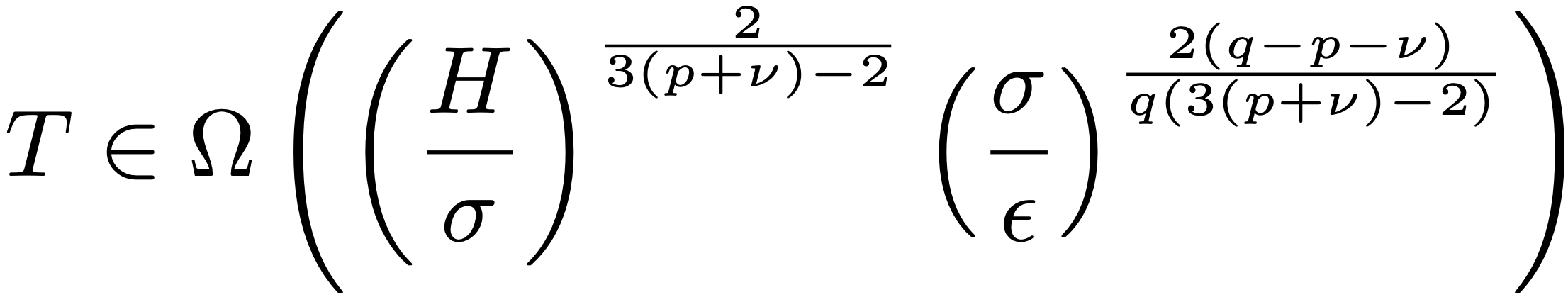Model immunization aims to pre-train models that are difficult to fine-tune on harmful tasks while retaining their utility on other non-harmful tasks. Though prior work has shown empirical evidence for immunizing text-to-image models, the key understanding of when immunization is possible and a precise definition of an immunized model remain unclear. In this work, we propose a framework, based on the condition number of a Hessian matrix, to analyze model immunization for linear models. Building on this framework, we design an algorithm with regularization terms to control the resulting condition numbers after pre-training. Empirical results on linear models and non-linear deep-nets demonstrate the effectiveness of the proposed algorithm on model immunization. The code is available at this https URL.
Home Publication Honors & Awards Courses & Skills Personal Curriculum Vitae